Synthetic Data Has a Governance Problem That Enterprises Are Not Ready For
As enterprises turn to algorithmically generated data to sustain AI development, a second-order problem is emerging — one that threatens model accuracy, regulatory compliance, and strategic differentiation.
Topics
News
- Sam Altman Floats Plan to Give US Govt 5% OpenAI Stake: Report
- UAE Unveils National Framework for Children's Content Across Media
- Palantir CEO Slams OpenAI, Anthropic Over AI Token Economy
- AI Dispatch: Revisiting Strategies and Stirring Up New Ones
- Microsoft, Inception42 Launch Seraj, a GPT-4.1-Based Arabic AI Model
- Nvidia Rival Etched Steps Out of Stealth With $5B Valuation
Two Sides of the Same Coin
Synthetic data delivers when it is tied to reality. The problem arises when it becomes reality—something it never should.
Case 1: UK’s Synthetic Open Banking Data
The UK’s Financial Conduct Authority (FCA) spent two years examining how synthetic data could tackle some of the most stubborn data problems in financial services. To do so, it convened the Synthetic Data Expert Group (SDEG) — a panel of 21 experts drawn from across industry, academia, and regulation, including representatives from Barclays, HSBC, Standard Chartered, Mastercard, and the Alan Turing Institute.
The Open Banking practice enables customers to share secure financial information with third parties—lenders, money-monitoring apps, and payment services—but only with their consent. Due to the sensitive and personal nature of transactional data, testing the systems carries serious privacy and legal risk. This is where synthetic data comes into play.
One SDEG member organization tested this directly.
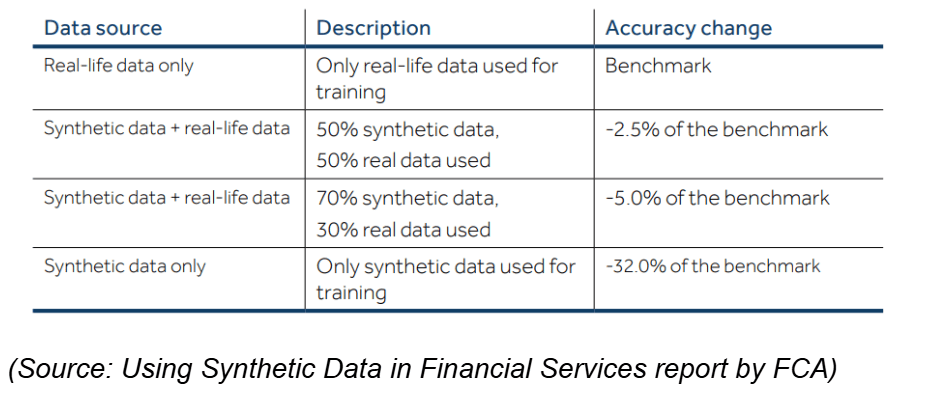
As a proof of concept (PoC), the project generated individual transaction descriptions, a text field containing transaction information, and an array of synthetic transactional data that, when aggregated to the customer level, replicated recognizable patterns of real income and spending behavior.
“It is not always the case of choosing whether to use synthetic data or real-life data. It is also important to understand the potential implications of having to remove some of the real-life data from existing training or validation sets, and evaluating the impacts on model predictiveness and accuracy,” the report stated.
The PoC’s preliminary findings indicated that, for this use case, a threshold of at least 30% real data, or an optimization of the real-to-synthetic data ratio, was needed to maintain strong model accuracy.