
Using Federated Machine Learning to Overcome the AI Scale Disadvantage
A promising new approach to training AI models lets companies with small data sets collaborate while safeguarding proprietary information.
Topics
News
- Core42 and Qualcomm Launch Compass 2.0 to Boost AI Efficiency and Accessibility
- Data Debt Emerges as Core Business Issue for Enterprises
- Are Organizations Investing in AI Achieving Positive ROI?
- Are Increasing Breaches Due to the Cyber Skills Gap?
- What Are the Challenges Firms in the UAE and Saudi Arabia Face in GenAI Implementation?
- Enterprises See the Promise of Generative AI But Lack the Guardrails to Mitigate Operational Risks

Jing Jing Tsong/theispot.com
Deep pockets, access to talent, and massive investments in computing infrastructure only partly explain why most major breakthroughs in artificial intelligence have come from a select group of Big Tech companies that includes Amazon, Google, and Microsoft. What sets the tech giants apart from the many other businesses seeking to gain an edge from AI are the vast amounts of data they collect as platform operators. Amazon alone processes millions of transactions each month on its platform. All of that big data is a rich strategic resource that can be used to develop and train complex machine learning algorithms — but it’s a resource that is out of reach for most enterprises.
Access to big data allows for more sophisticated and better-performing AI and machine learning models, but many companies must make do with much smaller data sets. For smaller companies and those operating in traditional sectors like health care, manufacturing, or construction, a lack of data is the biggest impediment to venturing into AI. The digital divide between big and small-data organizations is a serious concern due to self-reinforcing data network effects, where more data leads to better AI tools, which help attract more customers who generate more data, and so forth. This gives bigger companies a strong competitive AI advantage, with small and midsize organizations struggling to keep up.
The idea of multiple small-scale companies pooling their data in a jointly controlled central repository has been around for a while, but concerns about data privacy may quash such initiatives. Federated machine learning (FedML) is a recent innovative technology that overcomes this problem by means of privacy-preserving collaborative AI that uses decentralized data. FedML might turn out to be a game changer in addressing the digital divide between companies with and without big data and enabling a larger part of the economy to reap the benefits of AI. It’s a technology that doesn’t just sound promising in theory — it has already been successfully implemented in industry, as we’ll detail below. But first, we’ll explain how it works.
Small Data and Federated Machine Learning
FedML is an approach that allows small-data organizations to train and use sophisticated machine learning models. The definition of small data depends on the complexity of the problem being addressed by AI. In pharma, for example, having access to a million annotated molecules for drug discovery is relatively small in view of the vast chemical space. Other factors to consider include the sophistication of the machine learning technique, ranging from a simple logistic regression to a much more data-hungry neural network, as well as the accuracy needed for an application: For some AI applications (such as making a medical diagnosis), getting things right is simply more critical than for others (such as suggesting emojis when someone is typing). All else being equal, smaller organizations and those operating in traditional nondigital sectors are confronted with more serious data-related scale disadvantages.
FedML is an approach that allows small data organizations to train and use sophisticated machine learning models.
A few useful tactics and techniques have already been conceived to help companies struggling with this problem, such as cross-firm data pooling, transfer learning (repurposing previously trained models), and self-supervised learning (training a model on an artificial data set). Yet the centralized approach of data pooling may not be suitable in several situations, such as when there are legal constraints prohibiting data transfers or strategic concerns regarding sensitive data that should be kept private. Likewise, transfer learning and self-supervised learning are viable approaches only when a company can build on earlier insights from machine learning models performing tasks in related domains, which may not always be feasible. FedML can be a powerful extra instrument in a small-data company’s AI toolkit and serve as a critical complement to other small-data techniques.
In a federated learning setup, a machine learning model is trained on multiple decentralized servers controlled by different organizations, each with its own local data. They communicate with a central orchestrator that aggregates the individual model updates and coordinates the training process. (See “An Overview of Federated Machine Learning.”) In the simplest case, the learning objective would be to obtain basic descriptive facts of the data distribution, such as means or variances. Each company could, for example, compute the average failure rate of a certain manufacturing process at one of its plants and submit it to the orchestrator, which would then combine those individual contributions to form a more accurate joint estimate.
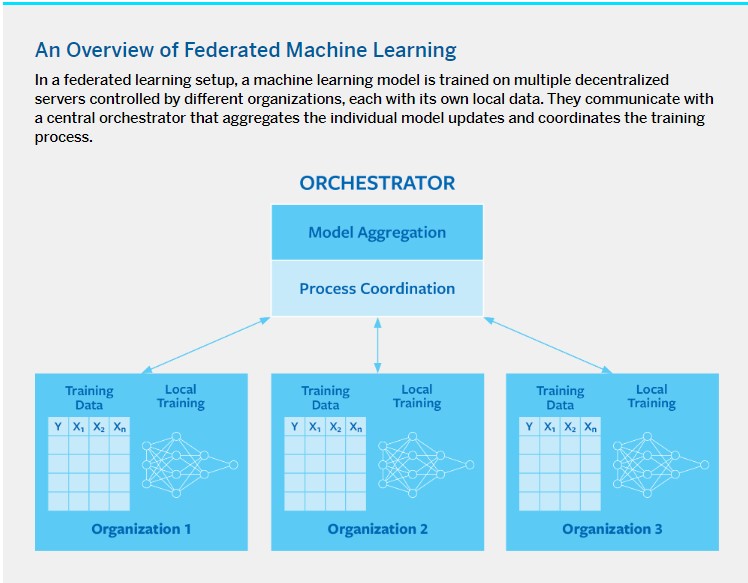
FedML is a distributed machine learning technique that can be used for a variety of algorithms. For example, the weights or gradients of a neural network can be averaged across organizations in a similar manner. The orchestrator is responsible for setting up the initial model architecture and coordinating the training process, which typically takes place over multiple iterations. As a result, companies can train complex machine learning models with a large number of parameters that would otherwise be beyond their reach, given that the constraints of their local data would lead to suboptimal model accuracy.
Importantly, raw company data stays private, and only statistical data, like estimated weights and other parameters, are shared and aggregated when FedML is applied. This way, 10 collaborating small-data companies that each have access to x data points could achieve roughly similar predictive power with their AI/machine learning applications as one much bigger company with access to 10 times x data points, without compromising data privacy.
FedML in Pharma
Innovation in pharma is very expensive and time consuming. The average cost to bring a new drug to market is around $2.3 billion as of 2022, and the process can take more than 10 years. One of the key difficulties in drug discovery involves the extremely high number of possible molecules (an order of magnitude of 1060) and the associated challenge of finding molecules with promising qualities in that vast chemical space. Against the backdrop of such steep costs and the sheer number of molecular possibilities, high-performing predictive machine learning models are the keystone of pharma’s AI-driven drug-discovery agenda. Pharma companies are also facing pressure as Big Tech players like Alphabet use their profound expertise in AI and machine learning to venture into drug discovery.
Cognizant of the reluctance to share drug discovery data, but also of the great potential of collaborative AI to boost efficiencies in drug discovery, Hugo Ceulemans, the scientific director at Janssen Pharmaceutica, began floating the FedML idea and initiating talks with peers around 2016. His efforts eventually contributed to the formation of the Melloddy consortium by 10 pharma companies in 2019. In a blog post, Ceulemans noted that while pharmaceutical companies had previously pooled data to support predictive efforts, the scope of collaboration had been limited, given that data is an expensive competitive asset. Because the new FedML consortium would allow the underlying data contributions to remain under the control of the respective data owners and not be shared, a much more ambitious scope would be possible, he explained.
Melloddy, a term named for machine learning ledger orchestration for drug discovery, was a three-year pilot project aimed at testing FedML for feasibility and effectiveness. The project was cofunded by the European Union; the European Commission considered Melloddy to be a test case for generating insights for business sectors beyond pharma. Participating companies included AstraZeneca, Bayer, GSK, Janssen Pharmaceutica, Merck, and Novartis, among others. These companies were supported by technology and academic partners, including Owkin (an AI biotech venture) and KU Leuven (a university with expertise in AI-driven drug discovery).
By leveraging one another’s data without actually sharing it, the participating pharma companies could train their machine learning models on the world’s largest drug-discovery data set, which enabled more accurate predictions on promising molecules and boosted efficiencies in the drug discovery process. In a blog post, Mathieu Galtier, chief product officer at Owkin, explained that thanks to Melloddy’s use of federated learning, data never left the infrastructure of any pharma partner. The machine learning process occurred locally at each participating pharmaceutical company, and only the models were shared. “An important research effort is devoted to guaranteeing that only statistical information is shared between partners,” he wrote.
The results of the Melloddy pilot project, which concluded in 2022, revealed that creating a secure multiparty platform for collaborative AI using decentralized data is feasible and that the performance of machine learning models is indeed enhanced by using a FedML approach.
Strategic Considerations for FedML Consortia
When setting up a FedML consortium, those involved in the planning process must carefully consider the optimal approach for orchestrating the technology and incentivizing partners. The selected orchestrator assumes a pivotal role in effectively managing the FedML process. Leaders of small-data organizations are sometimes reluctant to team up with Big Tech companies because they can maintain greater strategic control and build closer ties with smaller tech partners that operate on an equal footing. And some even fear that Big Tech companies will themselves move into their sector, as is happening in pharma.
In the case of Melloddy, pharma companies chose Owkin, a startup, to take on the responsibility of orchestrating the consortium’s FedML platform. This may be a good approach for many FedML initiatives, but it can be risky, given the high failure rate of startups: A consortium might crumble if the startup fails. There is also a potential risk that the startup might raise funding from a competitor that is not participating in the consortium; it’s an awkward situation, but not unlikely. Therefore, if a startup venture is chosen as the prime technology orchestrator, the consortium partners should seriously consider the option of investing corporate venture capital (CVC). When the partners have a sizable joint CVC stake in the startup, with rights of first refusal, they have much stronger control over the length of the tech startup’s runway and its future trajectory.
When taking first steps toward assembling a FedML consortium, securing partner buy-in is vital.
FedML can give rise to an incentive problem, wherein some participants fail to use all relevant local data or neglect to invest in the necessary data infrastructure to improve the accuracy of their local models. They may choose not to put in the effort while relying on the data contributions made by other consortium partners. This free-riding behavior then undermines the motivation and participation of well-intentioned participants. To preempt this problem, the FedML consortium can agree on appropriate partner commitments in terms of the quantity and coverage of data contributed and specify them upfront in a contractual agreement. Local model updates can also be monitored by the orchestrator in terms of their contribution to the overall accuracy of the joint model, and the payment of a FedML service fee can be made proportionate to each partner’s contribution to the federated learning process.
When taking first steps toward assembling a FedML consortium, securing partner buy-in is vital. Partners should therefore be involved in defining the consortium’s objectives in exchange for their data commitments. The AI Canvas is a decision-making tool that can be useful in identifying and discussing machine learning use cases and required training data. When approaching partners, keep in mind that effective model updates in most FedML applications require access to local data on all relevant model variables. As a result, suitable partners are often found within the same industry, sharing similar business processes and data. Working with indirect competitors, such as those serving other geographic markets, instead of with direct competitors could be advantageous here to minimize potential conflicts. For small-data organizations venturing into FedML, it’s advisable to start with achievable machine learning projects to establish momentum and build trust among partners before embarking on more ambitious projects.
FedML is still a young AI approach, developed in 2016 by a group of Google engineers. But progress in this field is fast paced, and we can expect a surge in its adoption across a range of business sectors. Forward-thinking leaders of small-data organizations who incorporate FedML into their strategic visions are better positioned to harness the transformative power of AI to shape their future success.



